Succesdrempel voor data-analyse in Human Resource Management ligt hoog
Succesdrempel |
 |
Nu data digitaal vastgelegd worden en beleidsmakers van hun adviseurs goed onderbouwde verklaringen en prognoses eisen, lijkt de toepassing van data-analyse in Human Resource Management vanzelfsprekend. Toch is dat niet zo. Met een casus, waarin geprobeerd wordt individueel en totaal personeelsverloop te voorspellen, wil ik laten zien dat de drempel voor succes hoog ligt. Waarom?
Omdat er geen klik is
Data-analyse is de wereld van de Bètas, waarin het draait om statistiek, software en andere abstracties van de realiteit, terwijl HRM meer de wereld is van de Alphas, die draait om echte mensen en dus om communicatieve vaardigheden, motiveren van mensen en kennis van regelgeving. Een klik is er dus niet, maar misschien is een geleidelijk groeiende samenwerking haalbaar. Data-analyse kan in elk geval de invloed van menselijke biases op analyses en beslissingen terugdringen. Wat kan data-analyse nog meer aan HRM bijdragen en hoe realiseer je dat? Een casus met echte data geeft antwoord.
De casus: Personeelsverloop verklaren en voorspellen
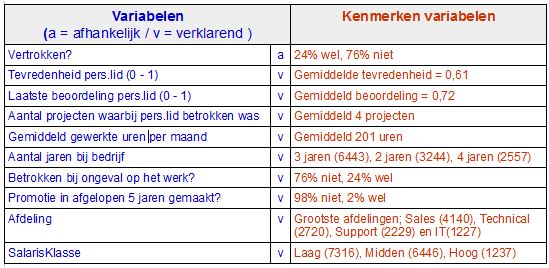
De casus omvat een dataset over 14.999 personeelsleden van wie elk tien kenmerken (variabelen) bekend zijn. Negen hiervan zijn potentiële oorzaken achter de tiende variabele, het wel of niet vertrekken van het personeelslid. Kan data-analyse aangeven welke van de negen oorzaken vertrek of blijven verklaren, zodat HRM-beleid hierop kan inspelen? U vindt het bestand hier: https://www.kaggle.com/ludobenistant/hr-analytics
Kwaliteitscontrole van de data leert dat er geen data ontbreken en dat het gemiddelde en de middelste waarneming van alle verklarende variabelen dicht bij elkaar liggen. Bij de afhankelijke variabele is de verdeling onevenwichtig; 11.428 van de p-leden zijn gebleven, dat is dus 76%.
Hoe hoog leggen we de lat?
We stellen natuurlijk graag een nauwkeurigheidsnorm voor onze data-analyse. We willen dat zoveel mogelijk voorspellingen over wel of niet vertrekken kloppen. Omdat 76% niet vertrekt, is het veilig om altijd te voorspellen dat een personeelslid niet vertrekt. Deze voorspelling klopt dan gemiddeld in 76% van de gevallen. Het te berekenen voorspellingsmodel moet dus vaker dan 76% juist zijn. De lat ligt daarmee hoog.
Werkt de traditionele manier goed?
We kennen allerlei kenmerken van de medewerkers en kunnen per kenmerk het gemiddelde vertrek berekenen. Als dit hoger ligt dan het algemeen gemiddelde vertrek van 24% is dit kenmerk een vertrekreden en als het lager ligt een blijfreden. Traditioneel werden data zo geanalyseerd; oorzaken werden onafhankelijk van elkaar berekend. In onze casus zijn dit de uitkomsten:
Een opvallend lager vertrek bij; Wel een ongeval op het werk, Wel een promotie in laatste 5 jaren, Afdeling management, Afdeling R&D, Salarisklasse Hoog, 7/8/10 jaar bij bedrijf en Betrokken bij 3 of 4 projecten.
Een opvallend hoger vertrek bij: Afdeling HR, Salarisklasse Laag, 4/5/6 jaar bij bedrijf en Betrokken bij 2,6 of 7 projecten.
Krijgen we dezelfde uitkomsten als we alle kenmerken tegelijkertijd analyseren?
Logistische regressie
Logistische regressie is een bijzondere vorm van statistische analyse en legt een verband tussen velerlei oorzaken en een binaire uitkomst (bijvoorbeeld wel/niet of goed/fout). In onze casus geeft ons logistisch model terugkijkend een nauwkeurigheid van 89,7%. Dat is veel beter dan de norm van 76%. We kunnen hier stoppen, maar is een andere statistische methode, de beslisboom, misschien nog beter?
Beslisboom veel nauwkeuriger
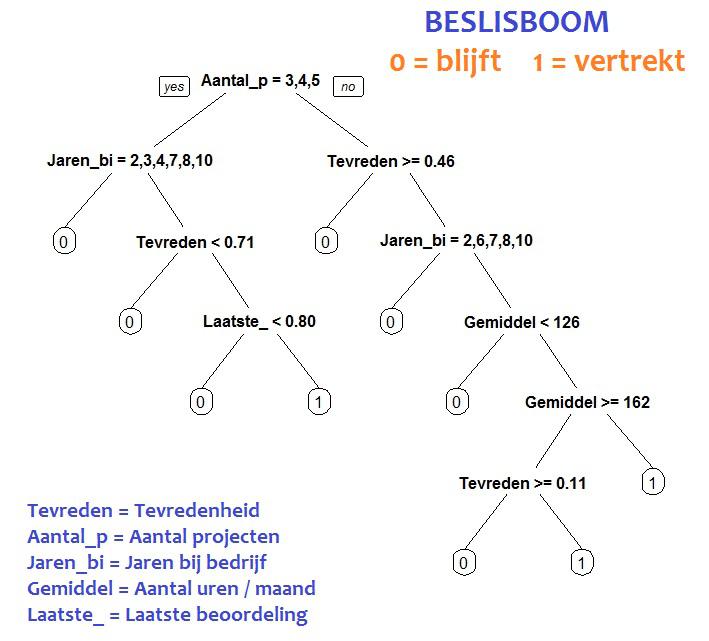
De beslisboom is een andere statistische techniek, meestal in de vorm van een grafische weergave van de alternatieven en keuzen in een besluitvormingsproces, Vanuit de top van de boom splitst elk tak zich (als ... dan ..., anders ...). Software berekent de optimale splitsingen, dus op welke variabelen gesplitst wordt en bij welke waarden.
In dit geval berekent de software terugkijkend een model met een nauwkeurigheid van 97%, wat hoog is. Dit is met bijgaande beslisboom afgebeeld. Uit de data blijkt echter ook dat het verband tussen de belangrijkste kenmerken en wel/niet vertrekken niet eenvoudig ligt en lastig te verwoorden is.
Twee voorbeelden in woorden:
"Als het aantal projecten 3 is en het aantal jaren bij het bedrijf 10 is, dan is er 97% kans dat de medewerker blijft”.
"Als het aantal projecten 8 is en de tevredenheid 0,80 is, dan is er 97% kans dat de medewerker blijft”.
| De software berekent ook het belang van de kenmerken in de beslisboom. Slechts vijf van de negen blijken relevant: |  |
De overige vier oorzaken (Ongeval op werk, Promotie in afgelopen 5 jaren, Afdeling en Salarisklasse) zijn - tegen de verwachting in - aantoonbaar onbelangrijk. |
Wat zegt deze casus over de drempel voor data-analyse in HRM?
Aantrekkelijk, en dus drempelverlagend, is dat data-analyse:
- nauwkeurig kan voorspellen en kan verklaren; in dit geval met een nauwkeurigheid van 97%,
- nauwkeurig de invloed van afzonderlijke oorzaken kan geven en
- het hele personeelsbestand, vertrekkers en blijvers meet. Oorzaken van vertrek zijn ook met exit-interviews goed te meten, maar nadeel hiervan is dat deze Eenzijdig zijn, want ze meten de blijvers niet. En dat doet data-analyse juist wel.
Geen drempel, maar wel een extra werklast vormt de noodzaak om het menselijke karakter, psychologie dus, in data-analyse voor HRM te verwerken. Juist in HRM wordt de grote invloed van perceptie, verwachtingen en persoonlijkheid in beslissingen onderkend, zoals bij wel of niet vertrekken. Vreemd genoeg spelen deze factoren in ons - desondanks nauwkeurige - model geen rol. Psychologische factoren zijn overigens met interviews en observaties goed te meten, welke metingen u in data-analyse kunt gebruiken.
Toch heeft deze succesvolle casus een keerzijde, want het laat de drempels in de toepassing van data-analyse zien.
- De uitkomsten van de beslisboom zijn niet eenduidig.
- Vernieuwende inzichten zijn moeilijk communiceerbaar. Het is zeker dat - in onze casus - personeelsverloop niet komt door het uitblijven van promotie, een laag salaris, een ongeval of werken op een bepaalde afdeling. Maar dat zal niet iedereen willen geloven, want deze vier zijn in de praktijk vaak wel redenen voor vertrek.
- De casus laat ook zien dat statistisch inzicht en vaardigheden nodig zijn om verschillende data-analyse-technieken uit te proberen, te interpreteren en te vergelijken op hun nauwkeurigheid.
- Er zijn verdiepende, dus meer data nodig. De duidelijke conclusie dat de tevredenheid de belangrijkste oorzaak van vertrek is laat toch een onvoltooid gevoel achter. Wat veroorzaakt deze (on)tevredenheid? En met welke akties kun je dit beïnvloeden? Dit toont de zwakte van deze casus en van data-analyse in het algemeen; we hebben een bijna perfect model, maar kunnen dit model (nog) niet omzetten in passende nieuwe akties en bijstellingen; we hebben daarvoor meer data nodig.
Maar we zijn wel een stap verder want we weten in welke richtingen (i.e. naar de vijf belangrijkste kenmerken) we verder moeten kijken.
614137 bezoekers (756355 hits) sinds 1-1-2009