Resultaten verbeteren met data-analyse
|
RESULTATEN VERBETEREN
met
DATA-ANALYSE |
 |
Deel 1 Nieuwe mogelijkheden
1.1. Doel van dit artikel
Data-analyse, meestal Big data en Business intelligence genoemd, staat sterk in de belangstelling. Terecht, want de mogelijkheden en het strategisch belang van informatie zijn sterk toegenomen.
Ik wil je laten zien hoe je van de toegenomen mogelijkheden gebruik kunt maken. Het artikel is een balans van enthousiasme oproepen voor de voordelen van data-analyse en het uitleggen hoe je data analyseert. In de kern is data-analyse statistiek, een discipline die ook door financiële mensen als lastig ervaren wordt.
Hoewel veel publiciteit rondom data-analyse van belanghebbenden komt, is het zeker geen hype. Op het gebied van geneeskunde en natuurwetenschappen zijn de resultaten indrukwekkend. Bedrijven met grote IT-afdelingen analyseren intensief hun data. Het is dus een beproefde methode voor beter beslissen. Maar in het midden- en klein-bedrijf blijft het gebruik achter. Dat zal door stimulerende trends echter snel veranderen. Ook voor het MKB is het halen van kennis uit data met data-analyse een manier om de harde concurrentie voor te blijven.
Dat vraagt actieve inzet van statistische technieken als regressie-analyse, het vastleggen van data om deze te analyseren, het opsporen van mogelijke verbanden, het doen van voorspellingen en het toetsen van deze voorspellingen aan de werkelijkheid.
Ik verwacht te laten zien dat data-analyse eenvoudiger is toe te passen dan velen denken. In de praktijk kunt je met eenvoudige hulpmiddelen, zoals Excel, veel zelf. Dat maakt het tevens goedkoop. Het beste is om met eenvoudige projecten (Hoe kan ik mijn omzet voorspellen?, Hoe voorspel ik het effect van mijn promotie?) te beginnen.
1.2. Wat te winnen met data-analyse?
Werden vroeger arbeid, financiering, grondstoffen en energie als de hulpbronnen van een bedrijf gezien, tegenwoordig wordt informatie, dat zijn bewerkte gegevens, net zo belangrijk geacht. Want informatie is nodig voor coördinatie binnen een bedrijf en om gefundeerde beslissingen (op alle niveau's) te kunnen nemen.
Enerzijds is informatie een belasting, omdat het een noodzakelijk, kostbaar kwaad is om het bedrijf te doen functioneren. Maar anderzijds is informatie een bron voor concurrentie-voordeel en is het goed bruikbaar voor de verbetering van bedrijfsprocessen en dus van de resultaten.
Bij data-analyse gaat het niet om het traceren van losse feiten of om het berekenen van gemiddelden, maar om het ontdekken van verbanden in data over:
-
genomen beslissingen,
-
resultaten en
-
oorzaken achter resultaten.
Data over dingen die echt gebeurd zijn. Met dit inzicht in verbanden kunnen effecten van mogelijke beslissingen, bijvoorbeeld hoe je je afzet promoot, voorspeld worden. Daarmee kan gefundeerd de beste optie gekozen worden. Bovendien kunnen daarna de voorspellingen aan de realisatie getoetst worden.
Het voordeel van data-analyse is dat u beslissingen mede kunt baseren op kennis gewonnen uit feiten en zo minder afhankelijk wordt van subjectieve intuïtie en ervaringen. Die kennis is niet het einddoel, maar is middel om geld te verdienen, dus om kosten te verlagen, omzet te verhogen, processen te stroomlijnen en kwaliteit van produkten en diensten te verhogen.
1.3. Trends die data-analyse stimuleren
De sterke belangstelling voor data-analyse is goed verklaarbaar. Een aantal trends bevorderen het gebruik.
A. Digitale data en communicatie
Binnen organisaties zijn bijna alle data en bestanden digitaal opgeslagen. De hele administratie wordt per computer verwerkt, maar ook spreadsheets voor ondersteuning en rapportages zijn digitaal. Zelfs facturen voor klanten worden steeds meer digitaal verzonden.
Veel communicatie, zowel intern als extern, vindt digitaal plaats via email, via websites of een vertaling van gesproken woord in digitale transmissie.
Digitale data en communicatie zijn machinaal leesbaar, dus makkelijker terug te vinden, uitstekend te bewerken en je kunt er eenvoudig en snel analyses op uitvoeren.
B. Bedrijfsprocessen digitaal
De produkten en diensten van organisaties zijn steeds vaker digitaal van vorm en niet meer fysiek. Muziek, boeken films, entreebewijzen, overheidsdocumenten en vele meer worden sneller en goedkoper digitaal geleverd. De digitale vorm maakt goede analyses ervan mogelijk.
Werden vroeger veel data over bedrijfsprocessen op papier vastgelegd, zoals ontvangst-bevestigingen, tellijsten en orderlijsten, tegenwoordig zijn ze bijna altijd digitaal.
C. Internet maakt data altijd en overal bereikbaar
Met het Internet kunnen computers data uitwisselen. Dat gaat snel en een limiet aan de omvang is er nauwelijks. Dit betekent dat een analist data van elke lokatie zonder drempel kan gebruiken (als hij dat mag).
D. Krachtige hulpmiddelen
Voor data-analyse zijn hulpmiddelen, zoals opslagmedia, processors en software, nodig. Deze hulpmiddelen zijn steeds krachtiger en tegelijkertijd steeds goedkoper geworden. Sommige software, zoals de programmeertaal R en OpenOffice Calc, is zelfs gratis omdat het door universiteiten en vrijwilligers is ontwikkeld.
E. Open data
Steeds meer overheden stellen hun data gratis beschikbaar aan het publiek. Voorbeelden zijn de Amerikaanse overheid (http://www.data.gov/) en de Nederlandse (https://data.overheid.nl/).
F. Doorbraak economische psychologie
In 2002 braken de inzichten uit de economische psychologie door toen Daniel Kahnemann, een psycholoog, de Nobelprijs voor Economie ontving. Hij toonde aan dat beslissers vaak minder rationeel zijn dan ze zelf denken en wensen. In veel situaties is dat 'automatisch denken' niet erg, maar bij belangrijke beslissingen zijn hulpmiddelen, zoals een second opinion of data-analyse, gewenst.
1.4. Data-analyse is geen hype
Veel publiciteit rondom data-analyse komt van bedrijven, die diensten en produkten voor data-anayse leveren en dus niet onafhankelijk zijn. Toch is data-analyse geen hype. Het wordt al lange tijd succesvol en op grote schaal toegepast door grote organisaties en wetenschappelijke onderzoekers. Vakgebieden als geneeskunde en natuurwetenschappen steunen sterk op data-analyse om effecten te meten en te voorspellen.
Binnen grote bedrijven wordt het toegepast voor kredietbeoordeling (banken) en het berekenen van verzekeringsrisico's.
Inmiddels zijn er veel data-analyse-bedrijven opgericht, waarvan Google de bekendste en succesvolste is, die zich richten op onderwerpen als sports-analytics, beleggingsselectie en marketing-effectiviteit.
Bedrijven steunen op hun bedrijfsprocessen; het is hun kern. Daar zit nog veel verbeteringspotentieel. De vele data uit die processen kunnen dat potentieel met data-analyse zichtbaar maken.
1.5. Hoofdlijnen van dit artikel
Deel 2
Dit hoofdstuk legt uit hoe je beslissingen verbetert. Data-analyse ondersteunt management-beslissingen door kennis uit data te destilleren, vooral over oorzaken achter gewenste effecten. Hiermee verdiep je kosten-baten-analyses en ben je minder afhankelijk van subjectieve intuïtie en ervaringen.
Deel 3
Met regressie-analyse kijk je terug in data en destilleer je rekenregels. Hiermee kun je gefundeerde voorspellingen over het effect van uw beslissingen doen. Die gebruik je om beslissingen en dus de resultaten te verbeteren. Ik bespreek de techniek van regressie-analyse en de toetsen waarmee je de kwaliteit van je analyse kunt vaststellen.
Deel 4
Velen weten het niet, maar Excel is voor regressie-analyse en statistische toetsen heel geschikt. Niet voor intensieve analyses, maar in het MKB is het goed bruikbaar. Ik leg uit hoe het werkt en hoe je het moet interpreteren.
Deel 5
Voor intensievere data-analyse is het programma R geschikt. R is een open source software-programma, dat universiteiten veel gebruiken. Het is gratis en de opdrachten in R zijn eenvoudig, maar krachtig.
Deel 6
Winnen expertsystemen het van experts? Nee, een combinatie van expert (intuïtie, beoordelings-vermogen, flexibiliteit, kunnen doorvragen) en rekenregels (onfeilbaar geheugen, objectief, nooit moe, consistent) blijkt in onderzoek het beste te scoren.
Deel 7
Hoe breng je je start-situatie in beeld?
Deel 2 Zo ondersteunt data-analyse management-beslissingen
Omdat er zoveel kan met data-analyse wil ik dit boek afbakenen. Daarnaast laat ik zien dat vaak betere management-informatie nodig is en dat dat met data-analyse kan. Door objectief oorzaken achter resultaten te ontdekken, verdiept data-analyse traditionele kosten-baten-analyses en helpt het managers daarmee te voorspellen en te beslissen.
2.1 Ruime termen, afbakening nodig
De nieuwe mogelijkheden scheppen een stroom nieuwe termen. De meeste zijn vrij ruim en overlappen elkaar grotendeels.
Big Data
Hiermee worden grote databestanden van welke aard ook bedoeld. Ze zijn nauwelijks met reguliere systemen te beheren, komen snel binnen en zijn divers. De data komen vooral uit transactieverwerking, internet en telecom. Big Data valt buiten dit artikel.
Business Intelligence (afgekort BI)
Dit is de aktiviteit waarbij gegevens omgezet worden in informatie en inzicht; populair gezegd 'begrijpelijk gemaakt worden'. Het gaat om diverse aktiviteiten als projectrapportages voor het management, periodieke resultaten-overzichten en analyses van klant- en produkt-winstgevendheid. Data-analyse is deel van BI.
Data-analyse
Dit is de vaardigheid om met data modellen (verbanden tussen oorzaken en gevolg) te maken zodat betere besluiten genomen kunnen worden. Met betere besluiten bedoelen we besluiten, die bijvoorbeeld lagere kosten veroorzaken, betere kwaliteit van de produkten en diensten, een snellere doorvoer door het bedrijfsproces en, als gevolg van deze effecten, meer winst opleveren.
Algoritme, model en formule
Het produkt van data-analyse is een rekenregel. Hiervoor worden in de praktijk veel verschillende termen gebruikt, maar met de termen algoritme, model, formule en rekenregel wordt hetzelfde bedoeld.
Het produkt van een data-analyse ziet er meestal zo uit :
Gevolg = (constante A * oorzaak 1) + (constante B * oorzaak 2) + Constante Waarde Gevolg + Onverklaarde factoren.
Een voorbeeld in cijfers : Afzet ijs = (11 * temperatuur) + (25 indien concurrent afwezig) + 40 + e
Supervised learning
Supervised learning is de techniek waarbij gericht gezocht wordt naar verbanden tussen oorzaken en een gevolg. Het stelt de vraag; "Wat is het verband tussen oorzaken X1 en X2 en gevolg Y?". Dit kan alleen als de data in een tabel vervat worden; het hoeven niet noodzakelijkerwijs getallen te zijn. Regressie-analyse (zie 3.2) is de meest gebruikte vorm van supervised learning en gebruikt alleen getallen. Bij unsupervised learning zoekt een programma op goed geluk naar mogelijke verbanden in grote data-verzamelingen. Dit wordt vaak bij Big Data gedaan, maar vanwege de nadelen valt het buiten dit boek. Nadelen van unsupervised learning zijn ;
- programma vindt vele verbanden, die bij nadere - tijdrovende - beschouwing slechts correlaties zijn, maar geen oorzaak-gevolg-relatie.
- programma vindt geen verband, terwijl een analist - door een oorzaak van buiten de onderzochte data-verzameling toe te voegen - wel een verband vindt.
Gestructureerde data
Data kunnen gestructureerd zijn of ongestructureerd. Ongestructureerde data, zoals emails, social media berichten en gesproken woord, worden anders geanalyseerd dan gestructureerde data. Ze zijn niet gebaseerd op getallen en kunnen niet in een tabel vervat worden en er kunnen dus geen onderlinge oorzaak-gevolg-relaties bepaald worden. Voor hun analyse worden aparte technieken als clustering, patroonherkenning en Markov-modellen gebruikt. Gestructureerde data passen in een tabel en daardoor kan met regressie-analyse naar onderlinge verbanden gezocht worden.
2.2 Oorzaken en hun sterkte achterhalen
Bij het analyseren van resultaten, zoals de behaalde omzet of de marge op een produkt, komt altijd de lastige vraag op in hoeverre dit resultaat nu het gevolg is van externe (dus onbeïnvloedbare) invloeden (zoals het weer of de concurrentie) of van de eigen beslissing (zoals een marketing-aktie of gekozen verkoopprijs). Bedrijfsresultaten zijn het gevolg van beide en het is gewenst te beoordelen wat de kwaliteit van elk van de eigen beslissing(en) was. Dit om - als nodig - te kunnen bijsturen en om de beslissers te evalueren. Een techniek om de oorzaken achter een resultaat objectief te bepalen is dus zeer gewenst.
In de praktijk blijkt niets zo demotiverend als om verantwoordelijk gehouden te worden voor (slechte) resultaten, die eigenlijk veroorzaakt worden door externe invloed. En waarom zou je beslissers prijzen of belonen voor resultaten, die te danken zijn aan gunstige externe invloed? Bovendien eist het kiezen van de beste bijsturings- of vervolg-akties dat u de oorzaken achter het resultaat kent.
Oplossing: regressie-analyse
Mogelijke oorzaken zijn meetbaar met getallen. Hun invloed op het gevolg is met regressie-analyse te achterhalen. Om dit te doen verzamelt u gedurende enige weken deze data om er daarna een regressie-analyse 'op los te laten'. Deze analyse toont de precieze kracht van elke oorzaak, zodat de kwaliteit van de eigen beslissing(en) beoordeeld kan worden.
2.3 Kosten-baten-analyses verdiepen
Het heeft een tijd geduurd, maar anno 2016 zijn kosten-baten-analyses normaal. Van zelfstandige aktiviteiten en projecten worden de opbrengsten en kosten zo goed mogelijk tegenover elkaar gezet om te beoordelen wat het tot dat moment opgeleverd heeft. Het toerekenen van opbrengsten is meestal geen probleem, maar voor kosten ligt het lastiger. Vooral het toerekenen van de grootste kostenpost, personele kosten, is een uitdaging. Organisaties hanteren verschillende methoden zoals Activity Based Costing, tijdschrijven of opslagpercentages, voor het toerekenen van de bestede tijd van personeel. Of overhead ('het hoofdkantoor') doorberekend moet worden hangt af van de vraag of die beïnvloedbaar is door de aktiviteit / het project. Gemiddeld ziet een kosten-baten-analyse er zo uit :
Voorbeeld Kosten-baten-analyse
Direct toerekenbare inkomsten 100
Af:
Direct toerekenbare kosten 40
Toerekenbare tijd medewerkers 30
Toe te rekenen overhead 20
Resultaat 10
Eigenlijk wordt een kleine resultatenrekening opgemaakt. Op basis van de doorberekenings-methode(n) en de werkelijke uitkomsten wordt dan boordeeld of deze resultaten goed of niet goed zijn.
-
Indien goed ; Herhalen of doorgaan.
-
Indien niet goed ; Schrappen of bijsturen.
Hoewel een oordeel nu mogelijk is, heeft een kosten-baten-analyse als nadeel dat je het waarom van het resultaat, en dan vooral van de inkomsten, niet kent. Lag het aan onbeïnvloedbare factoren als de temperatuur, de aktiviteit van concurrenten, aan de dag van de week of het seizoen of aan het onverwachte gedrag van klanten? Of lag het aan eigen beslissingen, zoals prijsstelling, de keuze van de marketing-aktie, de uitvoering van de marketing-aktie of de eigenschappen van het produkt?
Voor een goede beslissing is dus meer inzicht nodig in de oorzaken achter het resultaat. Dat kan met regressie-analyse.
2.4 Beperkingen van intuïtie en ervaring opvangen
Alle economische en financiële technieken gaan er van uit dat beslissingen rationeel genomen worden. Hoewel het als een grondslag gepresenteerd wordt, is rationeel beslissen niet meer dan een wens en een veronderstelling. Iedereen weet dat dit in de praktijk om veel redenen (tijddruk, teveel informatie, geen duidelijke voorkeur hebben, invloed van omgeving) moeilijk is. Het kwam dus niet als een verrassing dat in 2002 de psycholoog Kahnemann de Nobelprijs voor Economie won.
Hij bracht nadrukkelijk onder de aandacht dat mensen, en dus ook beslissers in organisaties, varen op intuïtie en ervaring en sterk beïnvloed worden door anderen en de omstandigheden. Niet uit luiheid, maar omdat in de complexiteit rationaliteit onhaalbaar is. Met veel onderzoek liet hij zien dat ;
- - ons geheugen selectief is,
- - we de makkelijkst beschikbare (vaak: meest recente) kennis gebruiken,
- - we ons vermogen tot schatten en voorspellen overschatten,
- - we een systematische voorkeur voor optimisme hebben en
- - we niet consistent in onze keuzes door de tijd zijn.
Kahneman beveelt aan, als de beslissing belangrijk genoeg is, second opions te vragen, niet impulsief te beslissen en hulpmiddelen te gebruiken.
Iedereen maakt in discussies bij beslissingen wel argumentaties mee die moeilijk te weerspreken zijn, maar die niet echt overtuigen, omdat ze oncontroleerbaar zijn. U herkent ze wel :
De ervaring leert dat ...
In mijn vorige functie werkte ... erg goed
Ik ben er van overtuigd dat ...
Op grond van mijn ervaring verwacht ik het meeste van ..., enz.
Gefundeerde voorspellingen kunnen de beperkingen van intuïtie en ervaring verminderen en meer rationaliteit in de discussie brengen. Bovendien bieden ze tegenwicht aan moeilijk weerspreekbare argumenten.
Deel 3 Zo werkt data-analyse
Goed geïnformeerde, veeleisende klanten en aggressieve concurrenten maken het steeds lastiger om een voorsprong te krijgen en te houden. Met data-analyse, het ontwikkelen en gebruiken van kennis uit gegevens, kunt u voor blijven. Het succesvolste voorbeeld dat het kan is zoekmachine en advertentie-bedrijf Google. Welke rol speelt data-analyse precies in de concurrentie-strijd?
3.1 Het nut van data-analyse
Verbind verleden met toekomst
Dat je het verleden niet meer beïnvloeden kunt betekent niet dat het zinloos is terug te kijken. Door oorzaken, zoals je beslissingen, en gevolgen hiervan, zoals je omzet, goed vast te leggen kun je een verband leggen tussen beide. Met een hulpmiddel, zoals regressie-analyse, kijkt je terug en spoor je relaties tussen oorzaken en een gevolg op. De opgespoorde relatie, bijvoorbeeld een rekenregel om de afzet a.g.v. een promotie-aktie te voorspellen, stelt je in staat om deze aktie met andere promotie-mogelijkheden te vergelijken en zo een betere beslissing te nemen.
Met data-analyse kun je beter voorspellen, doordat je oorzaak-gevolg-relaties opgespoord hebt.
"Terugkijken om vooruit te kunnen kijken"
Je kunt twee soorten voorspellingen doen :
A. Voorspellingen, waarvan je de oorzaken niet kunt beïnvloeden, zoals het weer of de aktiviteit van een concurrent.
Voorspellen is desondanks zinvol, want je kunt op de voorspelling inspelen door de meest optimale beslissing te nemen. Je stelt zichzelf - na de voorspelling - de vragen "Wat is het effect op ons?" en "Hoe kunnen we hiermee omgaan?". Bijvoorbeeld een ijsfabrikant doet - n.a.v. het weerbericht - met zijn rekenregel een voorspelling over de vraag naar zijn produkten en zorgt ervoor genoeg beschikbaar te hebben.
B. Voorspellingen, waarvan je de oorzaken wel kunt beïnvloeden
, zoals je marketing-akties, je personeelsbeleid, reacties van klanten en behandelmethoden van artsen. Je voorspelt de gevolgen van je mogelijke akties, zodat je de keuze met het hoogste effect kunt maken. Bijvoorbeeld een autoimporteur vraagt zich af : "Wat levert de meeste reacties op; een tijdelijke korting van 3% of gratis extra accessoires t.w.v. € 1.000?"
In de praktijk zijn veel voorspellingen gebaseerd op intuïtie of het doortrekken van trends. Dat is riskant. Regressie-analyse maakt betere voorspellingen mogelijk, doordat het de oorzaken achter gevolgen erbij betrekt.
Nog een voordeel : Oorzaken scheiden
Naast betere voorspellingen maakt data-analyse het mogelijk om oorzaken te scheiden en hun afzonderlijke kracht te bepalen. Bijvoorbeeld de ijsfabrikant kan bepalen - met regressie-analyse - wat de invloed van zowel de temperatuur als de aktiviteit van de concurrent op de afzet is. Dit is nodig om mensen te evalueren en om te zien of bijsturen zinvol is.
Wat data-analyse niet is:
Data-analyse zoekt naar oorzaken en geeft deze precies (met getallen) weer.
- Het zijn dus geen kengetallen, want die vatten samen of signaleren, maar gaan niet in op oorzaken.
- Het zijn geen beoordelingen (”Goed”), maar kunnen effect en de kracht van de oorzaak precies aangeven.
| Data-analyse maakt dus betere beslissingen over uiteenlopende onderwerpen als beloning, personeelsbeoordeling, produktvergelijking, marketing, voorraadbeleid, kredietbeoordeling, medische behandeling mogelijk. |  |
3.2 Regressie-analyse ; verbanden opsporen in databestanden
3.2.1 Drie methoden
Er zijn meer geschikte methoden denkbaar om verbanden in data-bestanden te vinden. De keuze wordt beperkt door de soorten data die je gebruikt. De beste methode voor een data-bestand, dat wil zeggen de methode met de hoogste verklaringskracht of voorspellingsjuistheid, ken je pas als je ze uitgeprobeert hebt en de uitkomsten vergelijkt. Dit zijn drie veelgebruikte methoden :
a. Lineaire Regressie-Analyse (LRA)
Deze methode legt het verband tussen oorzaken en een gevolg, bijvoorbeeld het verband tussen de oorzaken 'type transmissie', 'gereden snelheid', 'auto-volume' en het gevolg 'benzineverbruik'. Bij LRA kunnen de oorzaken en het gevolg alleen getallen zijn, dus geen klassen. De kwaliteit van het verband wordt gemeten met de R²; de mate waarin een model de variatie in het gevolg verklaart.
b. Logistische RegressieAnalyse (LogRA)
Deze methode legt het verband tussen oorzaken, die getallen, klassen of zelfs woorden kunnen zijn, en een binair gevolg, dus 0 of 1. In de praktijk staat dit voor:
goed / fout,
gunstig / ongunstig sentiment,
bevat wel / niet …,
of anders.
LogRA berekent de kans op elk van de twee mogelijkheden, die samen natuurlijk 100% zijn.
c. de Beslisboom
Dit is een visuele weergave van de verbanden in een bestand met de takken in een boom. Vanuit de top splitsten de takken zich. Elk tak splitst op de waarde van een belangrijke oorzaak en eindigt bij de waarde van een gevolg. Uw software berekent de optimale splitsingen. De beslisboom is beter dan LRA als de verbanden niet-lineair zijn. Dus bijvoorbeeld als Oorzaak A > 10, dan Variant X, maar als Oorzaak A <= 10, dan Variant Y. Oorzaken en gevolg kunnen elke vorm aannemen.
3.2.2 Statistiek blijft lastig
Veel mensen hebben moeite met statistische concepten en technieken. Toepassing in de praktijk blijft vaak achterwege, wat misschien komt doordat opleidingen te diep graven. Ik herhaal hier alleen de belangrijkste en direct toepasbare concepten voor u. Dat zijn :
- de opbouw van een rekenregel,
- de standaarddeviatie rondom een gemiddelde,
- R², een maatstaf voor de kwaliteit van een berekend model,
- het nut van een dummy-variabele,
- goede software voor het rekenwerk,
- de noodzaak van statistische toetsen (en hoe dat te doen) en
- een checklist om de kwaliteit van analyses te verhogen.
3.2.3 Data samenvatten in een rekenregel
Met regressie-analyse kun je verbanden in data-bestanden opsporen. Je start met het vastleggen van data, die je in de analyse wilt gebruiken. Wat niet vastgelegd wordt, kan niet gebruikt worden, dus het is zaak goed na te denken over welke data je in de analyse wilt betrekken. Een rekenregel heeft wiskundig deze opbouw ;
Y= (a*X1) + (b*X2) + constante + ruis
Dit betekent : Gevolg = (constante a * oorzaak X1) + (constante b * oorzaak X2) + Constante onderwaarde gevolg + Onverklaarde factoren
Je kunt de rekenregel zoveel oorzaken geven als je nodig vindt, maar je kunt er maar één gevolg in verwerken. De factoren Y (het Gevolg), X1 (oorzaak) en X2 (tweede oorzaak) krijg je uit waarnemingen, die je vastlegde in een tabel. In geval van bijvoorbeeld IJsafzet (Gevolg) zijn het Temperatuur (Oorzaak 1) en Concurrent aktief (Oorzaak 2). De andere variabelen (constante a, constante b, Constante onderwaarde en Onverklaarde factoren) destilleer je met regressie-analyse uit de vastgelegde data.
Eindresultaat : een rekenregel
Zodra je de variabelen kent kunt hiermee een rekenregel opstellen. Deze gebruik je om te voorspellen. Je vult de verwachte waarden voor de oorzaken in (X1 en X2) in en daarmee bereken je het verwachte gevolg. Met de rekenregel maak je zo een nauwkeurige en controleerbare voorspelling voor het Gevolg. Deze voorspelling kun je op een later moment vergelijken met de realisatie.
LET OP Toch is het niet zeker dat de voorspelling uitkomt (ondanks dat het model klopt), want je kunt X1 en X2 verkeerd voorspellen. Bijvoorbeeld de IJsfabrikant kan de temperatuur van morgen en de aktiviteit van de concurrent verkeerd voorspellen.
Hoe haal je een rekenregel uit data?
Het is natuurlijk ondoenlijk de ontbrekende parameters met de hand uit de data van de waarnemingen te berekenen. Daarom gebruikt je hiervoor software zoals SPSS, het programma Excel of de programmeertaal R. Iedereen heeft Excel beschikbaar, is er vertrouwd mee en het jeis voor eenvoudige regressie-analyse goed te gebruiken. R is gratis beschikbaar, heeft krachtige commando's en is geschikt voor lastigere opdrachten, maar moet geleerd worden.
Je software berekent de ontbrekende parameters door uit de duizenden mogelijkheden de lijn te kiezen met de minste afwijkingen tussen het berekende en werkelijk gemeten gevolg. Dat wordt uitgedrukt in R2, een getal om de kwaliteit van een rekenregel te meten. R2 leg ik in 3.2.4 uit.
3.2.4 Standaard-deviatie rondom gemiddelde
Vaak wordt een gemiddelde of een berekend getal gezien als een goede weergave van een groep getallen. Soms terecht, soms niet. Dat weet u pas als u de standaard-deviatie kent. Dit is de spreiding rondom het gemiddelde. Vergelijk bijvoorbeeld deze twee groepen getallen;
499, 500, 501 > Het gemiddelde is 500 en de standaard-deviatie is 1
450, 500, 550 > Het gemiddelde is ook 500, maar de standaard-deviatie is 50
Hoewel beide hetzelfde gemiddelde hebben, verschillen ze toch aanzienlijk.
De spreiding, bijvoorbeeld rondom een berekende parameter bij regressie-analyse, kan zo groot zijn dat de parameter niets betekent. Het is dus ook een toets op de geldigheid.
3.2.5 R², maatstaf voor kwaliteit
Een maatstaf om de kwaliteit van een rekenregel te bepalen is R², officieel de determinatie-coëfficient geheten. R² is de mate waarin een rekenregel de variabiliteit van de werkelijke data van het gevolg (Y) verklaart. Als alle berekende data in het model overeenstemmen met de werkelijk gemeten waarden, dan is R² = 1.
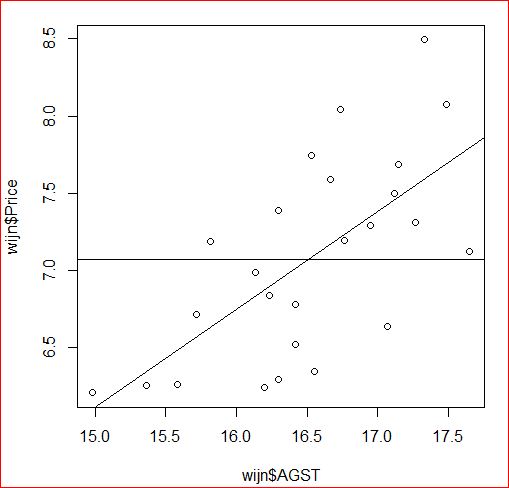 |
Bijgaand plaatje geeft een voorbeeld van een berekend model uit een verzameling waarnemingen. Gedurende 25 jaar werden de zomertemperatuur (wijn$AGST = oorzaak) en de prijs van wijn (wijn$Price = gevolg) vastgelegd. Er bleek een duidelijk, positief verband. Het model (de stijgende lijn) heeft een R² van 0,45 en verklaart daarom 45% van de variabiliteit rondom de gemiddelde prijs (de horizontale lijn). De oorzaak 'zomertemperatuur verklaart' dus 45% van de prijsbewegingen. Het betekent desondanks dat er meer oorzaken gezocht moeten worden om een hogere R² te krijgen en daarmee de prijsbewegingen goed te verklaren.
Je software, bijvoorbeeld Excel of R, berekent R² voor je. Het gebruikt daarvoor de data, welke je invoert, en kiest het model met de hoogste R². De uitkomst kan onbevredigend zijn, zoals bijvoorbeeld bij het voorbeeld van de zomertemperatuur en de prijs van wijn. Je kunt dan de R² verbeteren door nieuwe oorzaken, bijvoorbeeld neerslag, in de analyse te betrekken. In de praktijk worden alle mogelijke combinaties van oorzaken aan regressie-analyse onderworpen en wordt de combinatie met de hoogste R² gekozen.. |
3.2.6 Dummy variabelen zijn heel handig
Een dummy variabele kan, anders dan een getal, slechts twee waarden aannemen; een nul (= niet) of een één (= wel). Hiermee kunt u in uw analyse niet-getalsmatige oorzaken, die of wel of niet van toepassing, zijn betrekken. Uw software berekent tijdens de analyse hoeveel het gevolg (bijvoorbeeld de ijsafzet) verandert als de dummy (bijvoorbeeld 'Concurrent is aktief") de waarde één heeft.
Voorbeelden Dummy variabelen:
|
OORZAAK (= dummy variabele) |
GEVOLG |
|
0 : Geen promotie-aktie |
Effect op afzet |
|
1 : Promotie-aktie, 10% korting |
|
|
0 : Geen gladde wegen |
Effect op aantal schademeldingen auto's |
|
1 : Gladheid op wegen |
|
|
0 : Man |
Effect op frisdrankconsumptie |
|
1 : Vrouw |
|
|
0 : Niet merk P |
Effect op afzet |
|
1 : Wel artikel van merk P |
Een veel gemaakte fout is om teveel categoriën te gebruiken, bijvoorbeeld een categorie 'wel/geen man' en 'wel/geen vrouw'. Hierdoor wordt het model nietszeggend. Gebruik altijd n-1 categoriën. Als je bijvoorbeeld vijf merken analyseert, gebruik je vier (n-1) dummy variabelen.
3.2.7 Gebruik hulpmiddelen
Data-analyse is vanwege de bewerkelijkheid en de bijbehorende foutenkans onuitvoerbaar zonder software. Hoewel Excel op ieders computer staat en regressie-analyse hiermee eenvoudig is, blijft deze mogelijkheid vaak ongebruikt. Ten onrechte. Voor lastigere data-analyse is R geschikter, maar dit moet geïnstalleerd en geoefend worden.
3.3 Kwaliteit toetsen
3.3.1 Lastig & Vervelend
Het vinden van verbanden in data is relatief eenvoudig en leuk, maar het noodzakelijke vervolg, het toetsen van de uitkomsten op kwaliteit, is moeilijker. Het kan bovendien eindigen in een domper als de uitkomsten de toets(en) niet doorstaan. De kernvraag bij het toetsen is of de uitkomsten breed (i.e. buiten de data-verzameling) bruikbaar zijn. Hoewel er veel statistische toetsen zijn om dit te beantwoorden, zijn dit de vier belangrijkste:
- de logische toets,
- de verklaringskracht van de berekende rekenregel (de R²),
- de P-waarde (vaak T-toets genoemd) van de afzonderlijke variabelen in de rekenregel en
- kijken of de voorspelling uitkomt.
3.3.2 De logische toets
Statistische analyse draagt het risico in zich dat er wel verbanden gevonden worden, maar dat deze in de werkelijkheid geen oorzaak-gevolg-relaties zijn. Dit heet correlatie. Er bestaat bijvoorbeeld een sterke correlatie (want R² = 0,99) tussen het inwonertal van Frankrijk en de kwaliteit van wijn. Hoe meer Fransen, hoe beter de wijn? Nee, want beide hebben dezelfde oorzaak; door tijdverloop stijgt de wijnkwaliteit en groeit het aantal Fransen.
Je kunt correlatie vermijden door te toetsen op logica. Dat kan al bij de opzet, als je bedenkt over welke oorzaken je data wilt verzamelen. Kan het zijn dat deze oorzaak, bijvoorbeeld de temperatuur, bijdraagt aan het gevolg, de afzet van podukt X? Soms moet u hiervoor deskundigen, zoals de marketingafdeling, om raad vragen. Ook als je de uitkomst van de analyse heeft, moet je - nog eens - toetsen op logica. Dat kan met drie vragen :
- Kan het zijn dat deze oorzaak bijdraagt aan het gevolg?
- Kan het effect zo sterk of zo zwak zijn?
- Kan het effect positief (hogere temperatuur > hoger waterverbruik) of negatief (hogere temperatuur > lager bezoekersaantal) zijn?
3.3.3 De verklaringskracht van de R²
De R² is de mate waarin een berekend model de variabiliteit in de werkelijke data van het gevolg (Y) verklaart (zie 3.2.4). Zowel in Excel als R doet je software het (vele) rekenwerk om R² te berekenen. Het resultaat zegt iets over de kwaliteit over het hele model. Een R² boven 0,75 wordt als gunstig beschouwd. Maar als je een nog hogere R² wilt moet je nog een oorzaak (met de bijbehorende data) aan de analyse toevoegen.
In de praktijk wordt de data-analyse (en dus de berekening van de bijbehorende R²) uitgevoerd voor alle afzonderlijke oorzaken en mogelijke combinaties van oorzaken. De rekenregel met de hoogste R² wint.
3.3.4 De P-waarde (T-toets) van de variabelen
De P-waarde is de kans dat de berekende variabele eigenlijk niet bestaat, dus nul is. Hoe kleiner die kans, hoe beter natuurlijk. Meestal wordt een P-waarde kleiner dan 0,05 als voldoende klein beschouwd.
De P-waarde is een combinatie van :
- de T-statistic (berekende waarde / standaard-deviatie),
- het aantal vrijheidsgraden (= aantal waarnemingen van de oorzaak) en
- de tweezijdigheid van de toets.
Zoals gezegd doet je software het meeste rekenwerk. In R worden alle P-waarden automatisch en volledig berekend. In Excel bereken je de P-waarden met een tussenstap (standaard-deviatie/berekende waarde) en de opdracht T.VERD.
Als een variabele slaagt voor de test is de P-waarde daarna niet belangrijk meer. Als een variabele 'zakt' voor de toets, bijvoorbeeld omdat deze groter is dan 0,05, dan kun je de oorzaak negeren, dus uit de rekenregel verwijderen.
3.3.5 Komt de voorspelling uit?
Nadat je een rekenregel ontwikkeld hebt, kun je ermee voorspellen. Als je voorspellingen uitkomen is het een bruikbaar model. Je rekenregel bevat de uit je data-verzameling berekende constanten. Hierbij voeg je de verwachte waarden van de oorzaken, bijvoorbeeld de verwachte temperatuur en de verwachte aktiviteit van de concurrent. Daarmee voorspel je het verwachte gevolg; in dit geval de afzet van ijs. Deze voorspelling vergelijk je met de realisatie.
Deel 4 Data-analyse met Excel
De mogelijkheden van Excel zijn zo ruim dat de functies voor data-analyse vaak over het hoofd gezien worden. Ik bespreek de belangrijkste twee; het berekenen van lineaire functies en het statistisch toetsen.
4.1 Zo gebruik je Excel
4.1.1 De kracht van Excel
Niet voor niets is Excel populair. Deze pluspunten maken het ook voor data-analyse erg geschikt.
+ Veel functies
Als je de functiewijzer in Excel doorbladert zie je veel mogelijke opdrachten. Hoewel weinig gebruikt, is ook het statistisch aanbod ruim. Ik bespreek Lijnsch (zie 4.1.4) en T.verd (zie 4.1.6).
+ Handige wizard beschikbaar
Sommige Excel-opdrachten bestaan uit meer onderdelen. Dan is de functiewizard handig bij het invullen; je vergeet geen stappen.
+ Omzetten in ander format
Excel gebruikt de opmaak xls, maar kan ook data in een andere opmaak, zoals csv en ods, invoeren en uitvoeren. Dat maakt data uit Excel-werkbladen uitwisselbaar met programma's voor complexere berekeningen, zoals R (deel 5).
4.1.2 Nadelen van Excel
Ondanks de voordelen, heeft Excel beperkingen bij data-analyse.
- Vertaling blijft nodig
Functies in Excel, als Lijnsch, geven een nieuw blok data naast de ingevoerde data. Deze data moeten uitgelegd worden en vervolgens in spreektaal voor gebruikers vertaald worden. Dat is geen geringe, vaak onderschatte opgave.
- Krachtige opdrachten afwezig
Gespecialiseerde statistiek-programma's zoals R kennen tijdbesparende opdrachten, welke Excel mist. Zulke opdrachten moeten in Excel handmatig of met tussenstappen ingevoerd worden.
- Slechte help-functie
De help-functie in Excel blijft vaak onduidelijk. Het helpt nauwelijks bij het vertalen van de vragen "Wat moet ik nu doen?" en "Hoe los ik ... op?" in concrete opdrachten. Het legt vooral Excel-opdrachten uit, waarvan je de naam al kent.
- Amerikaanse decimalen
Waarschijnlijk heb je Excel standaard ingesteld op Nederlandse decimalen, dus Excel gebruikt de komma voor decimalen. Amerikaanse bestanden gebruiken hier echter een punt. Pas dus op met Amerikaanse bestanden of als je data opslaat om in R te gebruiken (dat werkt met Amerikaanse decimalen). Ook de Amerikaanse datum-aanduiding verschilt.
4.1.3 Statistiek
Bij welke data-analyse-uitdagingen kan Excel je ondersteunen?
a. Oorzaken scheiden
Met de opdracht Lijnsch kan je in Excel de oorzaken (X1, X2, enz) achter een gevolg duidelijk scheiden en kunt u bovendien hun afzonderlijke kracht bepalen.
b. Kunnen voorspellen
Met de opdracht Lijnsch bereken je de variabelen, waarmee je een rekenregel kun samenstellen om voorspellingen te doen.
c. Mitsen en maren aangeven
Rondom de berekende variabelen bestaat een onzekerheidsmarge. Die blijkt uit de standaarddeviatie van elke variabele (zie 3.2.3) en uit de R² van hele rekenregel (zie 3.2.4 en 3.3.3). Excel berekent deze allemaal automatisch met de opdracht Lijnsch.
d. Toetsen
Excel helpt je ook statistisch te toetsen. Het waarom en hoe van het toetsen wordt uitgebreider in 3.3 besproken. De toets R² wordt in Excel wel automatisch (met de opdracht Lijnsch) berekend. Maar de T-toets (3.3.4) moet je in twee stappen met de opdracht T.verd berekenen. Als je concrete voorspellingen wilt toetsen, moet je zelf de nieuwe data in de rekenregel invoeren en het berekende gevolg vergelijken met het werkelijke gevolg.
4.1.4 De opdracht 'LIJNSCH'
De opdracht 'Lijnsch' geeft als resultaat een tabel met de variabelen voor een rechte lijn die het beste overeenkomt met de dataverzameling op een Excel-werkblad. Je bepaalt wat het gevolg is dat verklaard moet worden en wat de oorzaken zijn om het te verklaren. Met de opdracht voer je een een groot aantal berekeningen in één keer uit, welke Exel uitrekent en in een matrix (een blok data) weergeeft.
4.1.5 Betekenis van het datablok van 'Lijnsch'
Het berekende datablok bevat de variabelen waarmee je een rekenregel kunt samenstellen. Hiermee kun je een formule uitschrijven. Het uitleggen van het datablok en het samenstellen van de rekenregel is best lastig vanwege de hoeveelheid informatie en de soms onlogische volgorde.
4.1.6 De opdracht 'T.verd'
De opdracht 'T.verd' gebruik je om de kwaliteit van de afzonderlijke variabelen te toetsen. Dit moet in Excel helaas in twee stappen.
Eerst bereken je de T-statistic (dit is de berekende waarde gedeeld door de standaard-deviatie). In de tweede stap gebruik je de opdracht T.verd. Hierbij kunt je het beste van de functiewizard gebruik maken.
Deel 5 De programmeertaal R
Voor intensieve data-analyse-projecten is het software-pakket R erg geschikt. De krachtige opdrachten ervan kunnen u veel tijd besparen. Ondanks de eenvoud is er toch een gebruiksdrempel; voor de meesten is R nieuw en het vergt zeker oefening.
5.1. Waarom R?
5.1.1. Pluspunten van R
Voor wie de mogelijkheden van Excel te beperkt en te tijdrovend vindt, is er een ruime keus aan statistische en data-analyse software. De keus van grote bedrijven is vaak SPSS, maar universiteiten kiezen vooral voor het relatief jonge R en voor het vergelijkbare Python. Belangrijke redenen; het is voor studenten gratis beschikbaar en er zijn legio gratis online cursussen. R is open source en de mogelijkheden groeien nog steeds.
Voor u heeft R de volgende pluspunten :
- R gebruikt de bestandsopmaak csv, herkenbaar aan de uitgang .csv. Vrijwel alle administratieve bestanden kunt u omzetten in csv. Dat kan rechtstreeks of het kan via een programma als Excel.
- R kan met een eenvoudige opdracht veel bewerkingen tegelijkertijd uitvoeren, wat in vergelijking met Excel veel tijd bespaart. We bespreken de opdrachten 'summary' (geef samenvatting van bestand), 'str' (geef structuur van bestand), 'lm' (bereken een lineair model uit bestand) en 'predict' (bereken een voorspelling met een model) in 5.2.
- Het programma is, met alle aanvullende pakketten, geheel gratis. Zelfs alle online opleidingen en grafische faciliteiten zijn gratis.
- R heeft opdrachten waarover Excel niet beschikt. Dat zijn bijvoorbeeld 'Step', waarmee R uit veel mogelijke combinaties van oorzaken (de X-en) de combinatie met de hoogste verklaringskracht berekent. En R berekent de 'Adjusted R²' automatisch, wat in Excel handmatig moet. Met 'sample.split' verdeelt R een databestand in twee zodat u het één kunt gebruiken om een model te berekenen en het ander om het te model te toetsen.
5.1.2. Nadelen van R
R heeft de volgende nadelen :
- De invoer van data en opdrachten luistert nauw. R biedt geen ruimte voor typefouten en accepteert geen lege velden (vanwege ontbrekende data); beide genereren foutmeldingen.
- Opdrachten in R leveren blokken met data op. Die vergen zorgvuldige bestudering om hun betekenis te ontcijferen. En daarna moet u ze nog omzetten in spreektaal.
- Vanwege het gratis karakter biedt R geen helpdesk. De help-functie is engelstalig en moeilijk begrijpelijk.
- R gebruikt de Amerikaanse decimalen-notatie (2.3 i.p.v. 2,3) en de Amerikaanse datum-aanduiding. Nederlandse bestanden moet u dus omzetten. Dat kan met Excel.
- R bestaat uit een grote basismodule. Sommige opdrachten kunt u echter alleen gebruiken door extra pakketten ('packages') als caTools te laden. Dat dat nodig is, is niet altijd duidelijk.
5.1.3. R en de opties ophalen
U kunt de laatste versie van R (R 3.1.2 for Windows) downloaden via :
http://cran.r-project.org/bin/windows/base/
Er zijn veel optionele packages beschikbaar. De lijst kunt u hier (http://cran.r-project.org/web/packages/available_packages_by_name.html) bekijken.
Voor dit boek heeft u alleen nodig ; caTools en ROCR. U haalt ze op door R te openen en achter de cursor (het >-teken) te typen :
install.packages("caTools")
In het keuzescherm kiest u de lokatie [bijv. Netherlands (Utrecht)] waar u het ophaalt.
Daarna typt u;
install.packages("ROCR")
Dit betekent niet dat u een pakket automatisch kunt gebruikt. U moet het steeds activeren voordat u het wilt gebruiken met de opdrachten :
library(caTools) en
library(ROCR)
5.1.4. R online gebruiken
Als u het installeren van R en de pakketten wilt vermijden of het risico van onbekende opdrachten kunt u een online-versie van R gebruiken:
- R On Cloud : http://www.roncloud.com
- CodingGround : http://www.tutorialspoint.com/execute_r_online.php
- R-Fiddle : http://www.r-fiddle.org
5.1.5. R gebruikt de CSV-opmaak
R gebruikt databestanden met de opmaak csv, wat CommaSeparated Vectors betekent. CSV-bestanden bevatten onopgemaakte data, welke van elkaar gescheiden zijn door komma's. U kunt CSV-bestanden bekijken met Kladblok en Excel. Voorbeelden vindt u op de website.
Om ze te kunnen gebruiken in R moet u uw data dus omzetten in CSV. Dat kan op twee manieren.
|
1. Open uw bestanden in Excel en sla deze - onbewerkt - weer op met de opmaak csv. Controleer met Kladblok of Excel of de data ook werkelijk door komma's gescheiden worden.
2. U kunt ook Excel-bestanden (herkenbaar aan de uitgang .xlsx achter de bestandsnaam) in R gebruiken. Voorwaarden : boven de kolommen staat de omschrijving EN alles behalve de data is verwijderd. Hiervoor heeft u het pakket xlsx nodig.
|
 |
5.1.6.Omgaan met Amerikaanse notatie
R gebruikt de Amerikaanse notatie van decimalen; een punt i.p.v. een komma. Dit betekent dat u 'nederlandse' bestanden moet omzetten in de Amerikaanse notatie; komma's (bijv. 2,3) worden punten (2.3). Dit kan door :
- het bestand in Excel te openen
- te controleren of het bestand werkelijk komma's gebruikt
- de tab 'Bewerken' te kiezen en vervolgens in het pull-down menu 'Zoeken en vervangen'
- Dan zoekt u naar , en vervangt deze door .
- Controleer het resultaat
- Sla het resultaat op in csv-opmaak.
Het leesteken . om duizendtallen te scheiden (bijv. in 12.500) moet u verwijderen omdat R het als een komma ziet (namelijk 12,500).
5.2 Opdrachten in R
5.2.1 Algemene opdrachten
In deze paragraaf beschrijven we u enkele handige opdrachten in R. Als u tegelijkertijd wilt oefenen opent u R en typt u de opdrachten achter de cursor (het >-teken). Het resultaat ziet u gelijk. We gebruiken het bestand 'R verhuur brondata.csv' dat u op de website vindt. Dit bestand bevat data die met de oorzaken Dag, Prijs en MooiBuiten (0 = gemiddeld weer / 1 = mooi weer) het gevolg Afzet (aantal verhuurde kano's) verklaren.

A. Voor u kunt beginnen:
1. Laad het bestand 'R verhuur brondata.csv' op uw computer
2. Controleer het bestand op lege velden, csv-opmaak en afwezigheid van komma's met Kladblok of Excel
3. Start het programma R
4. Wijs R naar de directory met het bestand met de tab File en vervolgens Change dir ...
B. Gebruiksklaar maken
Met de opdracht read.csv laadt u het bestand in R. Geef het een zelfgekozen (of identieke) naam.
5. Typ in R : verhuur=read.csv ("R verhuur brondata.csv") en toets op Enter
C. Bestand bekijken
R heeft twee handige opdrachten om een bestand grondig te analyseren op structuur en hoofdlijnen.
6. Typ in R : str(verhuur)
Als antwoord meldt R u dat het bestand 20 waarnemingen bevat met elk vier variabelen. Het geeft een handig overzicht hoe u naar de variabelen kunt verwijzen : verhuur$Dag, verhuur$Prijs, verhuur$MooiBuiten en verhuur$Afzet. Als u bijvoorbeeld de gemiddelde dagelijkse afzet wilt berekenen typt u ; mean(verhuur$Afzet).
7. Typ in R : summary(verhuur)
Als antwoord geeft R u vier tabellen die de inhoud samenvatten. Dat zijn de laagste waarde, de mediaan, het gemiddelde en de hoogste waarde.
5.2.2 Statistiek-opdrachten in R
Met R heeft u meer en snellere data-analyse-mogelijkheden dan in Excel. Met een eenvoudige opdracht schept u krachtige informatie uit uw data. Krachtige opdrachten zijn:
- LM Berekent een lineair model uit geselecteerde data
- Step Berekent uit alle data het model met de hoogste verklaringskracht
- Predict Vergelijkt de voorspellingen van een model met de werkelijkheid
- Sample.split Verdeelt een data-bestand in twee delen
We gebruiken om te oefenen weer het bestand 'R verhuur brondata.csv'.
A. LM
Met de opdracht LM berekent u een rekenregel met door u geselecteerde data. Als uitkomst geeft R data, die u gebruikt om een rekenregel samen te stellen en de uitkomst te toetsen.
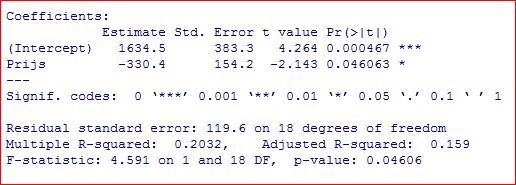 |
Dit datablok geeft u o.a. de volgende informatie :
|
Dit betekent:
- De Intercept (waar de rekenregel de Y-as snijdt) is 1634,5. Als de prijs € 0 zou zijn, zou de afzet 1634,5 zijn. De coëfficient voor Prijs is -330,4. Het min-teken betekent dat de afzet daalt als de prijs stijgt. Als de prijs € 1 stijgt, daalt de afzet met 330,4. Een prijsverhoging van 2,45 naar 2,55 resulteert dus in een afzetdaling van 33 [(2,55-2,45) x 330,4]. Formule voor de rekenregel ; Afzet = 1634,5 - (Prijs * 330,4)
- De P-waarden zijn erg klein, dus de kans dat de coefficienten nul zouden kunnen zijn, is gering.
- De R² van 0,2032 betekent dat deze rekenregel weinig verklaringskracht heeft; er moeten meer oorzaken in de rekenregel betrokken worden.
- De Adjusted R² corrigeert de R², maar is ook veel te laag.
Conclusie: Deze rekenregel met slechts één oorzaak verklaart de afzet onvoldoende.
B. Step
De opdracht Step bespaart u veel tijd als u uit veel mogelijke oorzaken het beste model moet berekenmen. Bijvoorbeeld in medisch onderzoek worden combinaties van tientallen oorzaken bezien voor het model met de hoogste verklaringskracht.
De opdracht Step probeert alle combinaties van mogelijke oorzaken (die u aanwijst) uit en kiest de combinatie met de hoogste verklaringskracht. Het gebruikt hiervoor niet de R², maar de AIC (Akaike's ‘Information Criterion). De AIC dient uitsluitend om mogelijke combinaties van oorzaken te vergelijken. De laagste AIC wint.
U gebruikt de opdracht Step in twee stappen:
- Eerst berekent u met LM een rekenregel, waarin u alle oorzaken uit uw dataset opneemt.
- Vervolgens berekent u met Step uit deze rekenregel de combinatie met de laagste AIC.
c. Predict
Met de opdracht Predict controleert u de juistheid van uw voorspelling(en) met het model dat u berekende. Hiervoor heeft u testdata nodig; nieuwe gegevens over oorzaken en gevolg. Die oorzaken gebruikt u om het gevolg te voorspellen, welke u vergelijkt met het werkelijke gevolg. Als die weinig afwijken, klopt het model. Als uitkomst krijgt u de waarden voor de voorspelde gevolgen op basis van nieuwe data over oorzaken.
d. Sample.split
Met de opdracht Sample.split kunt u een data-bestand in twee delen splitsen. U bepaalt hoe groot elk deel wordt door de SplitRatio in te stellen. Voordeel van het splitsen is dat u data kunt afzonderen om het model, dat u met de andere helft van de data berekende, te toetsen. U hoeft geen nieuwe testdata af te wachten.
Deel 6 De Expert contra het Algoritme
Je zag dat uit data kennis ontwikkeld kan worden, die uitgedrukt wordt in een algoritme. Met een algoritme kun je voorspellen en adviseren welkke akties het meeste effect opleveren. In de praktijk doen experts de meeste voorspellingen. Maar doen zij het beter?
6.1 De intuïtie van experts is beter
Ieder vakgebied kent experts; de aannemer voorspelt de duur en kosten van een bouwproject, een arts voorspelt het effect van een behandeling en uw marketingmedewerker voorspelt het effect op de omzet van zijn plannen. Hun expertise bouwen zij op met studie, ervaring en met het evalueren van het eigen functioneren. Een garantie voor succes is dat niet; het menselijk geheugen blijkt selectief, tijdsdruk maakt rationeel afwegen lastig en experts zien ook maar een deel van de wereld, zodat ze niet alles van hun vakgebied kunnen weten.
Bijvoorbeeld een wijnexpert kan niet alle wijnen geproefd hebben. Bovendien kunnen smaak-verschillen zo subtiel zijn dat zelfs de expert ze niet waarneemt. Als u een schaakcomputer met een schaakkampioen vergelijkt geldt hetzelfde; de keuzemogelijkheden zijn zo ruim en de gevolgen van een zet zo ver verwijderd dat alleen een computer de beste oplossing kan berekenen.
Een van de eerste grote successen in data-analyse komt uit 1990 toen professor Orley Ashenfelter in staat bleek de kwaliteit van wijn nauwkeurig te voorspellen voordat de druiven geoogst werden. Jarenlang had hij data verzameld over de gemiddelde zomertemperatuur en neerslag (de oorzaken) en de kwaliteit van de wijn (het gevolg) en hieruit een algoritme berekend dat aan het eind van de zomer de kwaliteit van de wijnoogst kon voorspellen (in 1990 : topkwaliteit). Dat jaar zaten de wijnexperts er naast, maar Ashenfelters voorspelling klopte.
Experts kunnen zoals gezegd niet alles weten, maar de volgende sterke punten hebben ze zeker:
- Experts kunnen kwalitatieve informatie, zoals meningen en beschrijvingen, goed beoordelen en verwerken. Algoritmen daarentegen hebben meetbare informatie nodig.
- Experts kunnen inspelen op wijzigende omstandigheden door hun strategie aan te passen. Algoritmen zijn meestal niet flexibel; er kunnen niet zo maar nieuwe oorzaken of gevolgen aan toegevoegd worden.
- Experts kunnen - als zij te weinig informatie hebben - doorvragen. Ze verzamelen net zo lang informatie tot ze verder kunnen. Algoritmen moeten het doen met de data die ze ingevoerd krijgen.
- Algoritmen worden doorgaans gebouwd op de kennis en ervaring van experts. Zij weten welke oorzaken een gewenst effect hebben of zij weten in elk geval in welke richting zij moeten zoeken. Experts zijn dus vaak betrokken bij het ontwikkelen van algoritmen.
6.2 Het Algoritme heeft een onfeilbare geheugen
Tegenover de sterkten van de expert zetten algoritmen hun eigen sterkten. Die hangen samen met hun enorme geheugen, rekenkracht en duidelijkheid.
- Algoritmen werken consist (zelfde data, dan zelfde uitkomst) en maken geen vergissingen, verschrijvingen of rekenfouten.
- Algoritmen hebben geen persoonlijke voorkeuren, ondervinden geen psychologische vertekeningen, zijn politiek en maatschappelijk neutraal en kennen geen emoties.
- Algoritmen worden niet moe en ondervinden geen tijdsdruk.
- Een algoritme brengt nadrukkelijk feiten, d.w.z. oorzaken en hun sterkte, onder de aandacht van de gebruiker. Het laat zien wat belangrijk is om een gevolg te bewerkstelligen. Dit maakt de feiten, maar ook de voorspelling of het advies bespreekbaar en opent de weg voor een kritische, zakelijke bespreking.
Nadelen van algoritmen zijn :
- de data moeten gestructureerd zijn (d.w.z. in een tabel passen),
- vooraf moet gecontroleerd zijn of de data verwerkbaar zijn.
- er kan langere tijd verstrijken voordat voldoende data verzameld zijn, bijvoorbeeld als men de invloed van bijzondere gebeurtenissen wil vaststellen.
En zoals gezegd; het algoritme krijgt de oorzaken aangereikt van experts en kan alleen werken met de ingevoerde data.
6.3 Onderzoek : combinatie is beste
Toch is het niet zo dat u moet kiezen uit de kennis van een expert of van een algoritme. Het is mogelijk beide te combineren en dat kan zelfs op twee manieren.
- Experts laten zich ondersteunen door algoritmen
- De gebruiker vraagt beide (Algoritme + Expert) en middelt (A + E / 2) de voorspellingen of adviezen.
Het onderzoek 'Database models and managerial intuition: 50% model + 50% manager' onderzocht negen situaties waarin managers gevraagd werd te voorspellen hoeveel omzet afzonderlijke items in een catalogus zouden realiseren en hoeveel kortingcoupons klanten zouden gebruiken. Hun voorspellingen werden vergeleken - aan de hand van de R² (de verklaringskracht) - met de voorspellingen van algoritmen. Het bleek dat nu eens de één dan weer de ander beter scoorde. Geen duidelijke winnaar, dus. Maar in alle negen situaties werden de scores (de R²) overtroffen door de managers, die een algoritme gebruikten en aanpasten aan eigen inzichten. Het onderzoek concludeert dat algoritmen de beperkingen van mensen verminderen. Om dat te bereiken moeten algoritmen vooral hanteerbaar en dus eenvoudig zijn.
6.4 Combineren
Omdat mensen de beslissingen nemen, maar niet onfeilbaar zijn, is ondersteuning met een algoritme aan te bevelen. Het werkt aantoonbaar beter. Het algoritme vervangt de expert dus niet, maar ondersteunt deze door missers te voorkomen. Belangrijk om het gebruik van een algoritme bij experts en andere gebruikers te bevorderen is, is hun eenvoud, d.w.z. het gebruikt maar een beperkt aantal oorzaken, die logisch verdedigbaar zijn. Experts kunnen hieraan bijdragen door hun kennis en ervaring zichtbaar te maken en vast te leggen in data, waarmee algoritmen berekend kunnen worden.
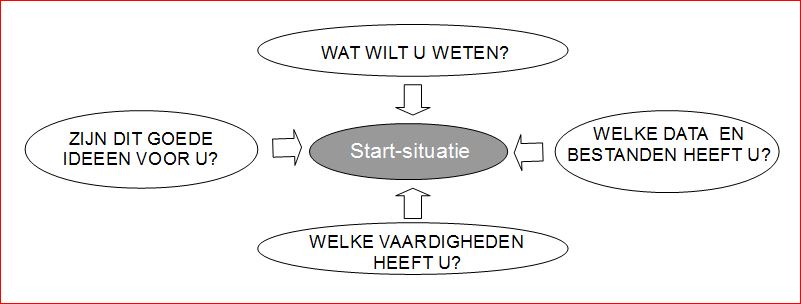
Deel 7 Bepaal uw start-situatie
Voor een goede start is het verstandig aan te haken bij wat je organisatie wel en niet kan en bij de wensen, die er al leven. Hiervoor is intern onderzoek nodig; noem het een combinatie van sterkte-zwakte-analyse en marktonderzoek. Een mooi start-project. Het project bestaat uit vier onderdelen, die je tegelijkertijd kunt uitvoeren :
a. Wat willen beslissers weten om hun beslissingen te verbeteren?
Met het risico van geringe respons kunt u beslissers vragen naar hun wensen.
b. Welke data en bestanden hebben we?
Om snel te kunnen starten en om lacunes op te sporen licht je de administratie door en interview je collega's om bestanden, die zij op eigen initiatief bijhouden, op te sporen.
c. Over welke vaardigheden, nodig om data-analyse uit te voeren, beschikken we?
Voor data-analyse zijn statistische kennis en vaardigheden nodig, maar ook een goede interview-techniek, de vaardigheid Excel en/of R te gebruiken en het vermogen data en statistische resultaten om te zetten in spreektaal.
d. Zijn dit goede ideeën voor u?
Je kunt de interesse onder beslissers stimuleren door concrete suggesties voor analyse-onderwerpen, waarvan je denkt dat ze aanspreken, voor te leggen.