Data-analyse vraagt andere kijk op data
Data-analyse |
 |
Nauwkeurige modellen vragen flexibele data
De sterke opkomst van data-analyse, of zo u wilt; Big Data, maakt een andere kijk op de grondstof van deze aktiviteit nodig. Het is niet alleen de grote hoeveelheid data die nieuwe mogelijkheden schept, maar het flexibel kunnen omvormen en inzetten van data maakt deze mogelijkheden zelfs nog groter. Die flexibiliteit krijgt ten onrechte weinig aandacht. Data-analyse vraagt deze flexibiliteit, want het beoordeelt data op hun relevantie, dat is de mate waarin data bijdragen aan de nauwkeurigheid van voorspellende en verklarende modellen. Ik wil laten zijn hoe flexibel data kunnen en moeten zijn.
De gewenste flexibiliteit staat echter op gespannen voet met de tradionele kijk op data, waarin deze origineel, volledig en vooral juist moeten zijn.
Data-uit-data
|
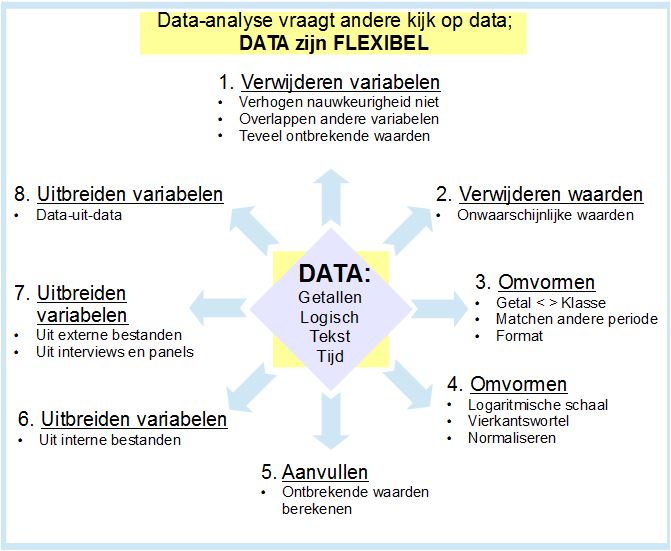 |
Omvormen van waarden (4 in schema)
In sommige gevallen zijn de waarden van variabelen lastig of niet hanteerbaar (vanwege het kwadrateren bij het berekenen van modellen geven ze een vertekend beeld). Of de waarden, zoals bij de lengte van tijdschrift-artikelen, zijn onevenwichtig verdeeld. In andere gevallen hebben de variabelen verschillende grootte-intervallen, bijvoorbeeld tientallen versus duizendtallen. Methoden om de nauwkeurigheid van het model te verhogen zijn het omvormen van zulke data naar:
- een logaritmische schaal,
- hun vierkantswortel en
- hun genormaliseerde waarden.
Aanvullen van waarden (5 in schema)
In data kunnen gaten vallen; er ontbreken waarden. Veel statistische pakketten maken het mogelijk de ontbrekende waarden te schatten. Ze doen dat door op de ontbrekende waarden dezelfde verbanden van toepassing te verklaren als tussen de niet-ontbrekende waarden en de overige variabelen. Zo berekent het pakket wat de ontbrekende waarden waarschijnlijk geweest zijn.
Uitbreiden variabelen met data-uit-data (8 in schema)
Data bevatten veel meer informatie als je ze bewerkt, combineert, relativeert of ontleedt. Dat kan op een aantal manieren.
a. Samengevatte informatie ontleden
Sommige data, zoals een tijdstempel, bevatten veel samengevatte informatie, die ontleed kan worden in zijn onderdelen. Een tijdstempel van een transactie of een persoonlijk contact kan ontleed worden in:
- jaar
- maand
- dag van de week
- uur van de dag
Er worden dus vier nieuwe variabelen uit een originele variabele geschapen. Deze vier kunnen gebruikt worden om klantengedrag te verklaren, patronen te ontdekken (invloed van seizoen en weekdag bijvoorbeeld) en gedrag te voorspellen.
Ook identificatiecodes, zoals tenaamstelling (geslacht), Universele ProduktCode (land van oorsprong / vendor / produkt) en webadres van een krantenartikel (datum / rubriek / titel), kunnen vaak ontleed worden in belangwekkende data.
b. Losse informatie over een object samenvatten
Losse data over een persoon, organisatie of object kunnen samengevoegd worden in een samenvattend gegeven. Bijvoorbeeld met data over het koopgedrag van klanten over het afgelopen jaar, over hoe zij benaderd zijn en over hun persoonlijke kenmerken, kan elke klant ingedeeld worden in een van de gebruikte klantentypenp. Evenzo kunnen - om het winkelbezoek te voorspellen - weerdata worden samengevat in de data- klassen 'Gunstig', 'Ongunstig' en 'Neutraal'.
c. Absolute data omzetten in relatieve data
In veel situaties betekenen absolute data weinig, omdat de grootte van de objecten die zij beschrijven verschillen. Dan worden absolute data omgezet in relatieve, zodat een veelzeggender variabele onstaat en dus een beter model. Als je bijvoorbeeld de kwaliteit van middelbare scholen wilt verklaren zegt het slagings-percentage meer dan het aantal geslaagden, omdat scholen in omvang verschilen. De nieuwe variabele 'Slagingspercentage' wordt berekend uit het aantal geslaagden en het aantal examen-kandidaten.
En het succes van een matching-site, gemeten als 'Wel of geen match', blijkt niet zozeer afhankelijk van de absolute leeftijden van de klanten, maar wel sterk van hun leeftijdsverschillen. De variabele 'Leeftijdsverschil' moet berekend worden en is een nieuwe variabele.
d. Beschrijvende data scheppen
Soms is het mogelijk een data-verzameling in een beschrijving door nieuwe variabelen samen te vatten. Deze treden dan niet in de plaats van de originele data, maar vullen ze aan om zo een nauwkeuriger model te berekenen.
Dit gebeurt veel in tekst-analyse, waarbij niet alleen de woorden zelf, maar ook beschrijvende variabelen gebruikt worden om het aantal lezers of de lezerswaardering te voorspellen. Uit een tekst kun je bijvoorbeeld de nieuwe variabelen 'Aantal woorden', 'Gemiddelde zinslengte', 'Sentiment' en 'Titel bevat vraagteken' berekenen.
Beschrijvende data kun je ook uit je klant-historie halen, waarin heel verschillende variabelen over contacten en transacties liggen opgeslagen. Die kun je samenvatten in een nieuwe variabele 'Wel/niet eerder bij ons gekocht' of 'Aantal dagen sinds laatste bestelling'. Deze variabelen gebruik je om commercieel succes te voorspellen.
e. Combineren met andere, extern verzamelde variabelen
Geografisch bevolkingsonderzoek bevat interessante economische informatie. Maar hoe kun je deze gebruiken? Ik denk hier vooral aan de postcode van particulieren, die niet alleen de woonplaats, maar ook de welstand en het inkomen indiceren. Met de postcode kunnen dus nieuwe variabelen als 'Welstand' en 'Inkomen' geschapen worden.
Creativiteit en uitproberen
Data-analyse vraagt dus toch creativiteit (Stel jezelf de vraag "Welke data verhogen de nauwkeurigheid van voorspelling of analyse?) en het volhardend uitproberen van de mogelijkheden van data-uit-data. Maar, is het zelf maken van data dan geen luchtfietserij? Nee, de verhoging van de nauwkeurigheid door deze data is gelijk het bewijs dat de data-uit-data kloppen.
608534 bezoekers (749200 hits) sinds 1-1-2009